
こんにちは、ラングです。
2022年頃から一気に活性化してきた「AI イラスト」。現在では様々なツールが各所で作られており、一般の人々でも(利用規約の範疇で)自由に使ってイラストを描ける…というか生み出せる時代になりました。
時代の進歩を感じますよね~
同じ人物やキャラを多角度・複数で出力するのは難しいと思いますが、風景や単発出力であれば高精細なイラストを自分のイメージで素材似できてしまうのは結構有用性高いんじゃないでしょうか。
さて。
そんなAIイラストを抽出できるツール「Stable Diffusion」を導入していく過程をちょっと記していこうかと思います。
導入過程
3つのパターンの内「PC版」でやります
「Stable diffusion」の利用方法は Web/アプリ版サービス・クラウド版インストール・PC版インストール の3パターンに区分できますが、今回はPC版インストールでやることにしました。
Web/アプリ版サービスは大半が利用制限ありだったり月額料金制になってますが、スマホで使えるのもありますね。クラウド版は使用しただけ料金がかさむのがネックですが、高性能なPCでなくとも利用できるのが特徴です。
対してPC版インストールは、自分のPCで画像生成を行うために高性能のPCが必要となります。反面、料金を抑える or 無料で使えるのが大きいです。そのため今回はPC版でやっていきます。
導入したPCのスペック
CPU:Intel Core i7-4770
メモリ:16GB
グラボ:NVIDIA GeForce GTX 1660 SUPER
結構な化石スペックですが一応画像生成はできました。生成中にメモリ使用量をかなり食っているようなので、使い倒すなら直近のゲーミングPCを用意した方が快適だと思います。
- おすすめのPCストア
- 「STORM」…映える光の白ケースPCが魅力
- 「パソコンショップSEVEN」…ZEFTシリーズから色々選べる
- 「アーク」…ノートPCなどの選択肢あり
導入ソフト
今使っているPCがWindowsなので、対応するインストールソフトを活用させていただきます。
「NMKD Stable Diffusion GUI - AI Image Generetor」
これをこちらのサイトさんからダウンロード。
[Download Now] ボタンからダウンロード可能。
(寄付の画面が出ますが、No thanks~のリンクから無料で入手できます。寄付で応援されたい方はご自由に)
ファイル形式は7zで圧縮されてるので、対応する解凍ソフトを用意しましょう。ちなみに俺は7-zipで行いました。
>参考:「窓の社」圧縮・解凍ソフト一覧
ちなみにファイル容量をかなり取られるので、利用するドライブの容量は最低でも15GB以上は空けておきたいところ。
ダウンロード→解凍(展開)でけっこう時間がかかります。
終わるまでは何か別のことしておくといいかもですね。
解凍が終わったら、そのフォルダを開いて「StableDiffusionGui.exe」を起動。
WelcomeメッセージをチェックしてOK。
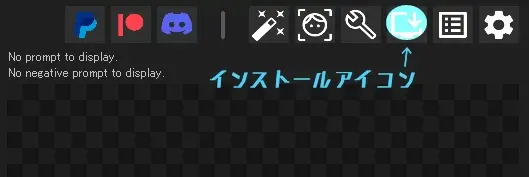
右上にアイコンが並んでいる。
そこでインストールアイコンを選び、Installerメニューを出す。
「Install」ボタンでいくつかの要素を追加インストール。
ONNX/DirectMLファイルをダウンロードする?という画面が出た際、GPUがAMD製なら必要らしいので「Yes」。俺の場合はNvidia製だったので「No」にしました。
次にアップスケーリングモデルについての事前ダウンロードを聞かれますが、これは「Yes」。
ダウンロードが始まったら、左下の方に進捗が表示されるので終わるのを待ちます。
終わったらinstallメニューを☓で閉じる。
画像をジェネレート
プロンプト(呪文)を入れて生成
上記で環境導入したので、実際に画像を作り出してみる。
まず、画面の左上に注目。
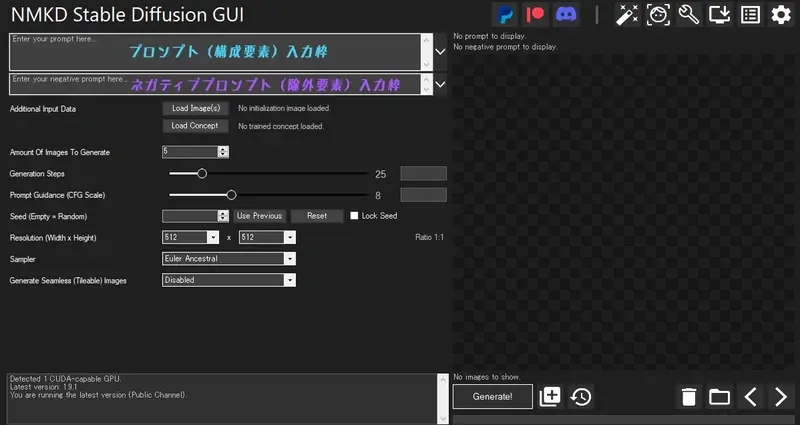
上の枠に画像の構成要素となるプロンプト、俗に言う呪文を入れる。
下の枠はネガティブプロンプトといい、画像生成から除外したい要素を指定できる。
その他、出力画像数やサイズの指定など複数のメニュー項目がありますが、一旦試しに「Generate」ボタンで画像生成してみました。
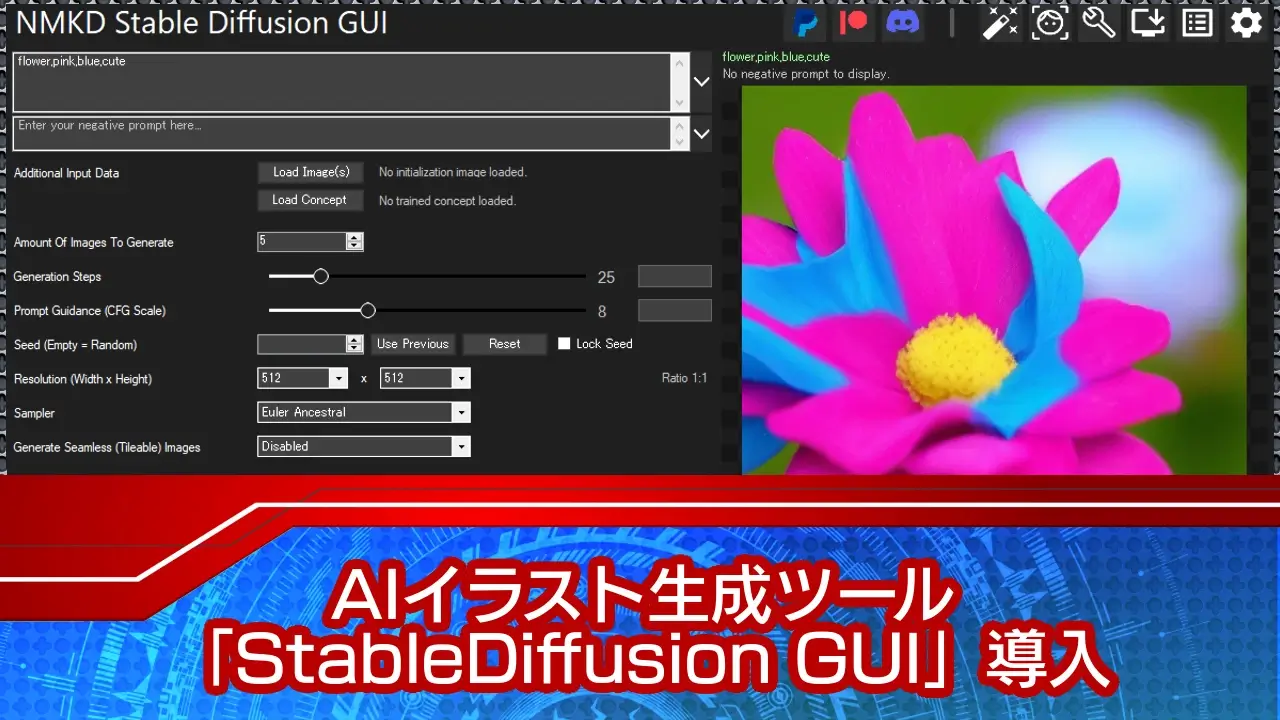
プロンプト:flower,pink,blue,cute
ネガティブ:(空欄)
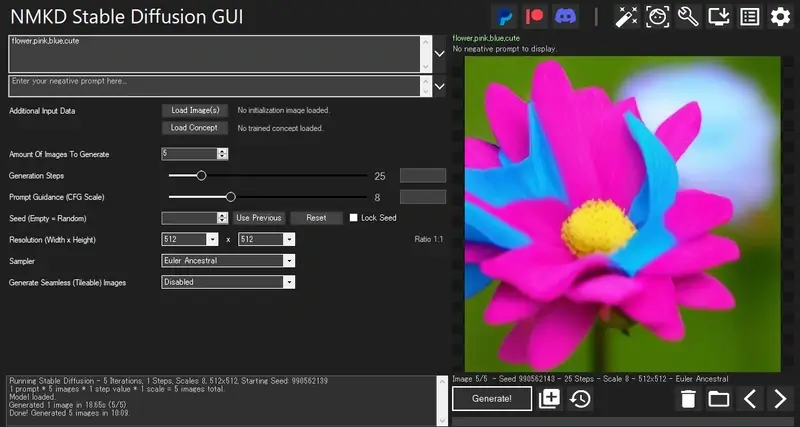
1回目の生成には5~10分ほどかかりましたが、上記のような画像が指定枚数(今回は5枚)生成されましたね。
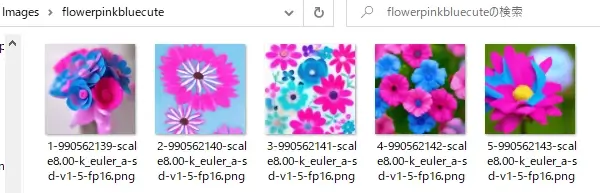
ちなみに生成画像は「StableDiffusionGUI」を最初解凍したファイルに「Images」があり、その中にプロンプトで打ち込んだファイル名でまとめて生成されているっぽいです。
イメージした画像を作るには…
この記事執筆時点ではまだお試し程度しか触れてないですが、イメージした画像に近いものを生成するにはいくつか必要なものがあるっぽいです。
プロンプトの具体性
いや、正確性というべきなのか?
プロンプト枠には様々な構成要素を入れることができます。イメージに近づけるには、要素をできるだけ具体的に正確に…つまり抽象的になりすぎてはいけないということですかね。
画像の学習モデル
初期導入版でもそれなりの画像は生成できるんです。が、アニメや漫画っぽいイラスト風なものを生成する場合は困難を極めそう。すでにネットで提供されている画像の学習モデルを追加導入した方が早そうですね。この辺は調べてみましょう。

しかし、時代の進歩は早いですね~。極めた人は高クオリティなイラストをどんどん生成してますし、頑張って勉強していこう。




自由に使ってイラストを描ける…というか ){kind=link}